混合专家模型(Mixture-of-Experts,MoE)是机器学习与深度学习中常见的模型架构,尤其在近年来的大模型研究与应用中被广泛采用。
MoE 的核心思想是:通过门控(Gating)机制对多个专家子模型的输出进行加权组合,在保证模型容量的同时提升整体预测质量。
MoE 架构
MoE 主要由两部分组成:
- 专家(Experts):一组相互独立的子模型,每个专家擅长处理特定类型的输入或任务。
- 路由器(Router/Gating Network):根据输入计算各专家的权重,并决定哪些专家被激活参与计算。
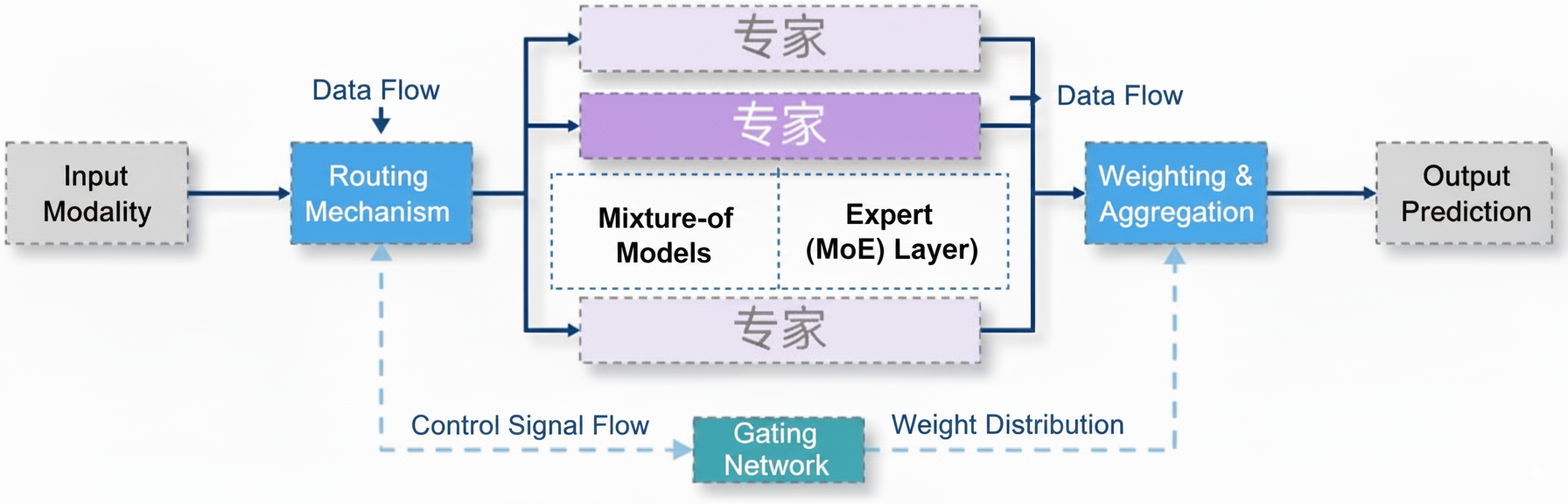
MoE 工作原理
MoE 的计算流程一般包括三个步骤:
- 路由:输入首先进入路由器,路由器为每个专家计算权重或激活概率。
- 专家计算:输入被分派给若干个专家子模型,分别完成前向计算。
- 结果融合:各专家输出根据权重进行加权集成,得到最终结果。
这种“按需激活”的机制,使得模型能够实现“分工合作”,针对不同输入调用更合适的专家。
稠密与稀疏 MoE
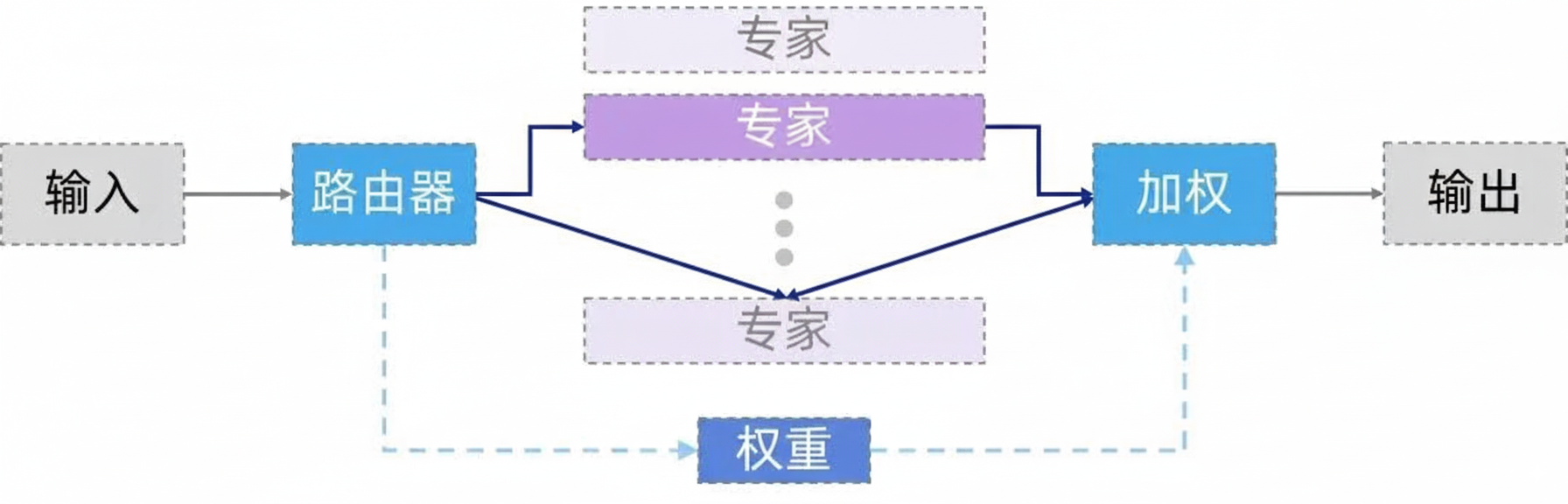
根据激活的专家数量,MoE 可分为两类:
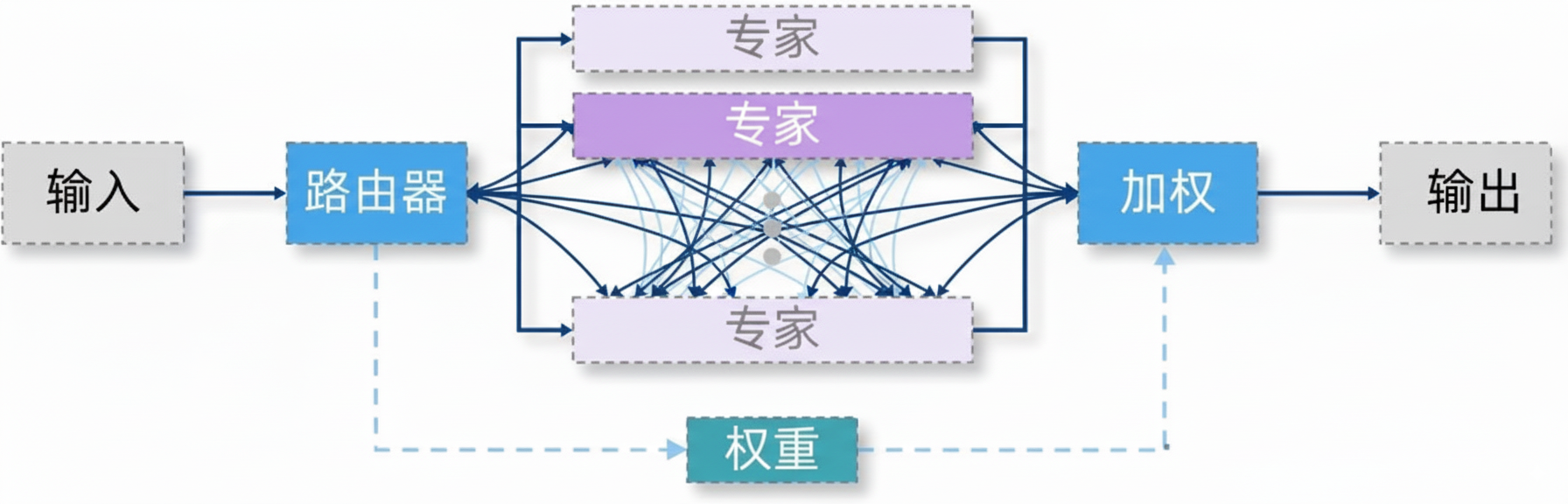
- 稠密 MoE:所有专家同时参与结果集成,模型容量大但计算成本高。
- 稀疏 MoE:仅激活权重最高的部分专家,显著降低单次前向传播的计算量,是当前大模型的主流方案。
Transformer 中的 MoE
在现代大模型中,Transformer 架构是基础。MoE 的常见用法是将标准 Transformer 中的前馈网络层(FFN)替换为稀疏 MoE 层:
- Experts:MoE 层中的每个 Expert 对应一个独立的 FFN。
- 路由器:通过门控网络计算各 Expert 的激活概率,通常选择前 K 个专家执行计算。
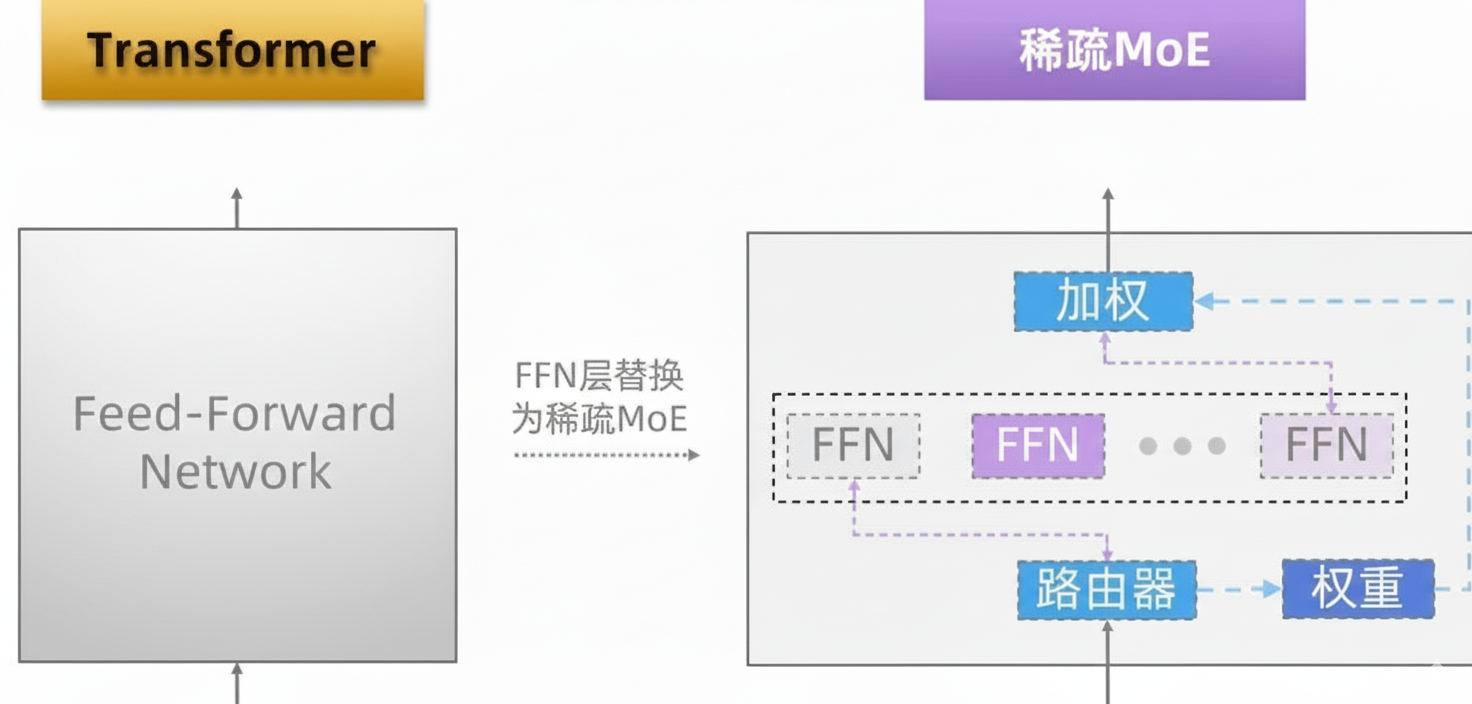
通过这一替换,模型既能保持大容量带来的表达能力,又能有效控制推理成本。因此,MoE 已成为“高容量、低计算”大模型设计中的核心组件之一。